Data Type Classification (Preview)
You need to have a clear picture of the data in your cloud environment in order to better manage your assets, and their security. Panoptica helps you classify the data discovered in your resources, through automated scanning, customized rules, and manual tagging. Data type classification helps identify sensitive elements, such as personal data. It also provides insights into your data landscape, enabling you to prioritize protection measures and ensure that sensitive information is adequately safeguarded
Data Types and Classes
There are four categories of Data Types that can be applied to your assets in Panoptica:
- Personally Identifiable Information (PII)
- Protected Health Information (PHI)
- Payment Card Information (PCI)
- Secrets
Data Classes are based on a combination of content and context. Content is identified by matching to predefined patterns, or heuristic rules indicating high correlation to that pattern. Context refers to associated metadata used to accurately classify the data. For example, capturing a date is not enough to identify a date of birth; the date also needs to be associated to a person's birth.
| Class Name | Description |
|---|---|
| Credit Card Number | A credit card number is between 12 to 19 digits. https://en.wikipedia.org/wiki/Payment_card_number |
| Email Address | An email address identifies an email box to which email messages are delivered |
| IBAN code | The International Bank Account Number (IBAN) is an internationally agreed system of identifying bank accounts across national borders to facilitate the communication and processing of cross border transactions with a reduced risk of transcription errors. |
| IP address | An Internet Protocol (IP) address (either IPv4 or IPv6). |
| Location | Name of politically or geographically defined location (cities, provinces, countries, international regions, bodies of water, mountains |
| Name | A full person name, which can include first names, middle names or initials, and last names. |
| Phone number | A telephone number |
| Medical License | Common medical license numbers. |
| US Bank Account | A US bank account number is between 8 to 17 digits. |
| US Driver's License | A US driver license according to https://ntsi.com/drivers-license-format/ |
| US Passport Number | A US passport number with 9 digits. |
| US Social Security Number | A US Social Security Number (SSN) with 9 digits. |
Sensitivity Levels
Panoptica then assigns sensitivity levels to your assets, according to the data patterns of the detected data. By default, the asset sensitivity level is set to the maximal severity of the detected data class.
- Very sensitive - The most sensitive level of classification represents information of utmost importance and confidentiality within the organization. These assets typically include highly confidential data such as personal health information (PHI), financial records, trade secrets, and other proprietary information. Access to and handling of this data should be strictly controlled and monitored to prevent unauthorized disclosure or misuse.
- Sensitive - While not as critical as the most sensitive data, these assets still require a significant level of protection due to their potential impact on the organization if compromised. Examples of sensitive data may include personally identifiable information (PII), intellectual property, employee records, customer data, and certain financial information. Access controls and data protection measures should be in place to safeguard this information from unauthorized access or disclosure.
- Moderately sensitive - Data classified as moderately sensitive refers to information that, while not as critical as more sensitive data, still warrants a certain level of protection and confidentiality. This category may include data that is not directly tied to personal or financial information but still holds value to the organization, such as internal communications, non-confidential business documents, and general operational data. While less sensitive, measures should still be in place to ensure the integrity and confidentiality of this information.
Managing Data Classification
There are various methods you can use to identify and manage the types and classes of your data in Panoptica, from full automation to manual assignment.
Automatic Data Classification
When onboarding your cloud accounts, you have the option of enabling Data Scanning, which automatically identifies sensitive data and secrets. The results are then correlated with other risk factors to enhance risk detection and prioritization.
Panoptica automatically scans for sensitive data in a variety of structured and unstructured file types:
| Category | File Type | Data type |
|---|---|---|
| Delimited Text | csv | Structured |
| JSON | json | Structured |
| Spreadsheet | xls | Structured |
| Spreadsheet | xlsx | Structured |
| Plain Text | txt | Unstructured |
| Plain Text | log | Unstructured |
| XML | xml | Structured |
| Document | docx | Unstructured |
| Document | Unstructured |
Panoptica does not store any of the scanned data – only metadata results, such as database schema.
Scanning Process
Data scanning occurs daily, following the workload scan of your cloud assets. If a storage resource is detected, the data scan starts:
- The account is checked for scan permissions and configuration. See Scan Settings below.
- Bucket objects are listed and queued for scanning
- Object data is analyzed by the classification engine
- Each object’s findings are stored in a DB.
- Findings are displayed in the data subtab of the Asset Details, in the Data Inventory tab.
Automatic data classification is only available for AWS accounts at the moment. Panoptica uses a natural language processor as well as pattern matching to detect PII, PCI, PHI data in your S3 buckets. Make sure to enable Data Scanning in the AWS Onboarding procedure.
To add data scanning to an account that has already been onboarded, you need to edit the configuration in the Settings – Accounts tab, and relaunch the CloudStack.
Optimizing the Scans
To help you economize, we have taken the following steps to minimize costs incurred in using the get_object action to run the data classification scans.
- Limitations: To reduce costs and avoid performance issues, the classification scan is limited to:
- 5 subfolders per bucket.
- 100 files per folder.
- 20MB of data per file.
- Optimizations: Panoptica only scans files that have been changed since the last scan (last modified > last scanned).
Panoptica's data classification service runs in two regions:
- us-east-2 (Ohio)
- eu-central-1 (Frankfurt)
The classification service can analyze buckets in any region, but you will save on data transfer costs scanning buckets in those two location.
See AWS CVE Scanning - Cost Estimation (COPY) for details on scanning costs.
Scan Settings
If you have enabled automatic data classification, Panoptica will scan all files by default. You can configure the scope – or even suspend scanning altogether – to improve efficiency and lower processing loads.
To configure the scan settings, browse to the Settings tab in Panoptica's main navigation pane, select Data Security, and go to the Scan Settings subtab.
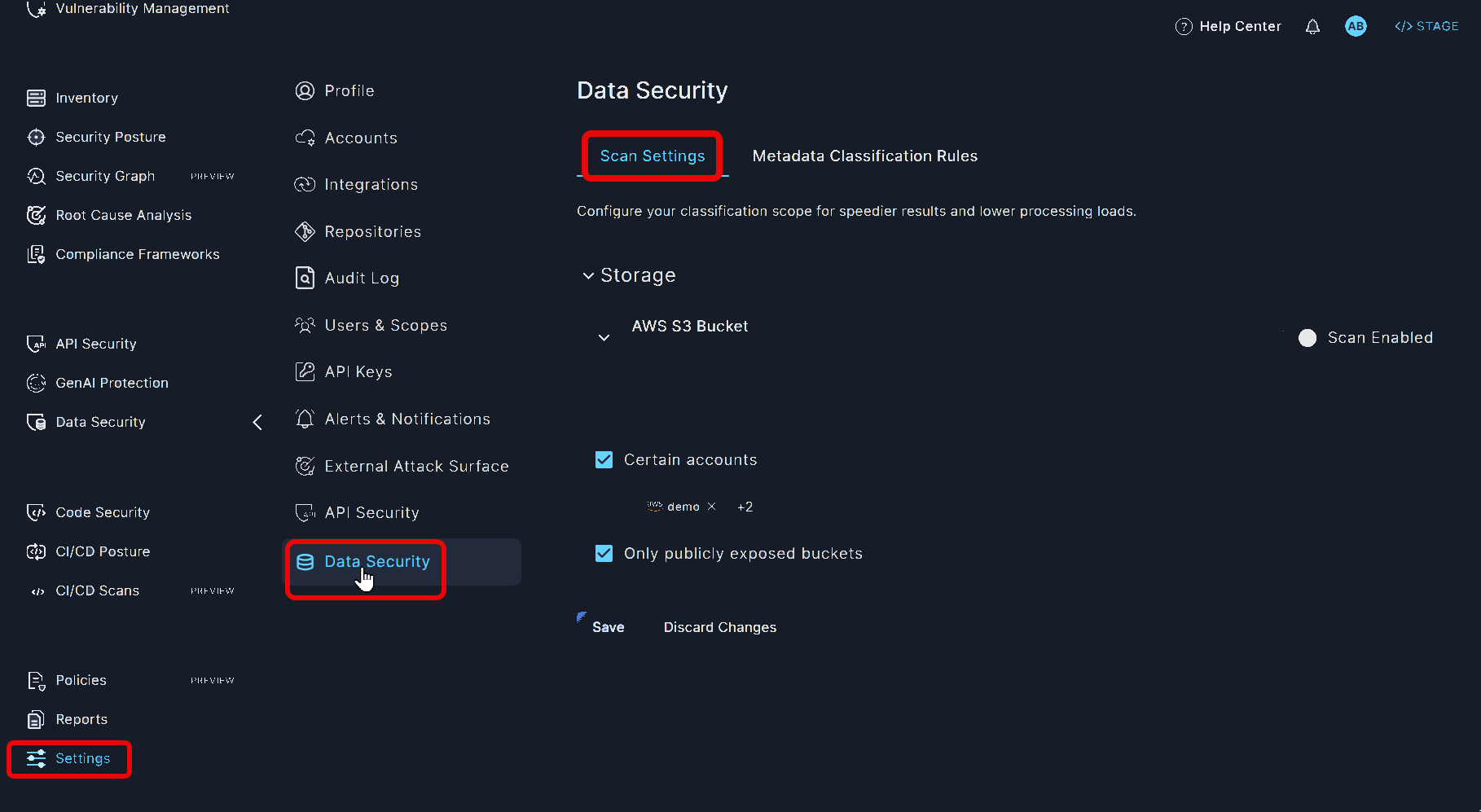
- To temporarily suspend scanning, click the toggle to disable Scan Enabled
- To limit scanning to only the accounts you want to examine, select Certain accounts and enter the account names.
- Drilling down, you can set more specific criteria such as specific accounts or assets matching certain conditions, such as publicly exposed.
- To limit scanning to only publicly exposed buckets, check that box.
Don't forget to click Save.
Metadata Classification Rules
Panoptica enables you to create classification rules based on metadata matching of your data. Constructing your own rules is useful when automatic data scanning does not meet your needs, or to apply established conventions your organization already has in place.
To configure and maintain classification rules, browse to the Settings tab in Panoptica's main navigation pane, select Data Security, and go to the Metadata Classification Rules subtab.
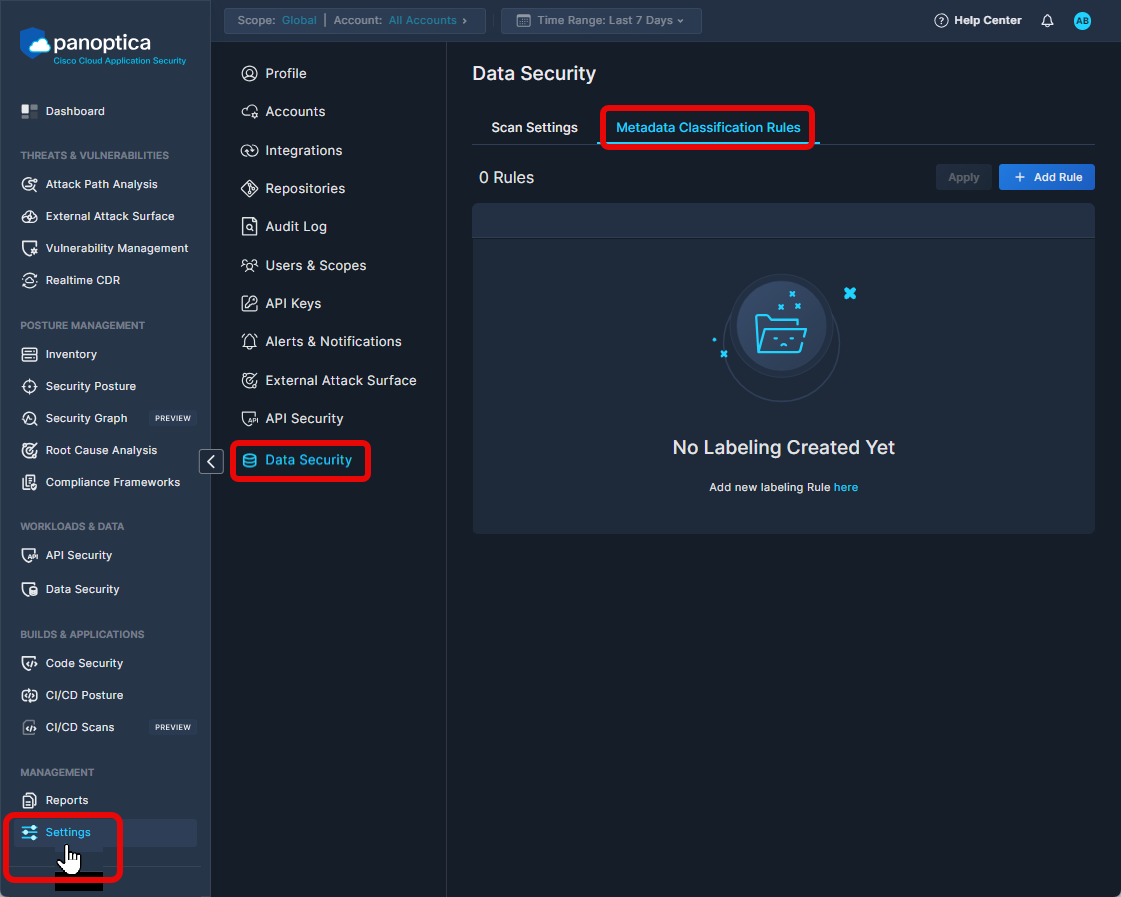
Click + Add Rule to open the Metadata Classification Rule overlay, where you can start defining rules.
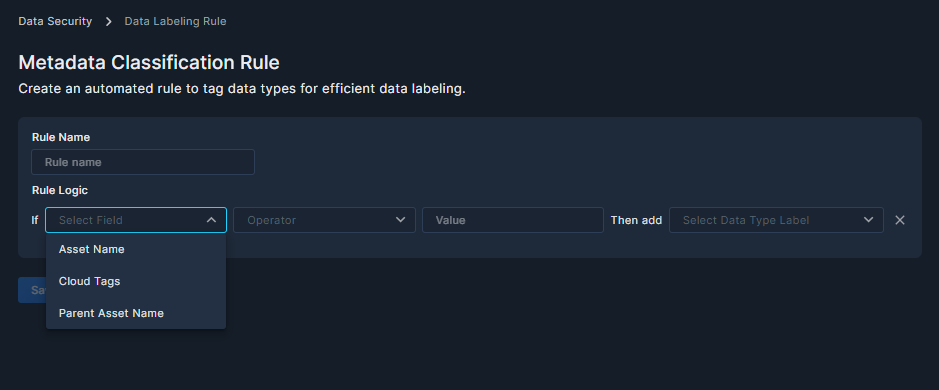
- Give your rule a logical name.
- Define the rule logic, starting with Asset Name, Cloud Tags, or Parent Asset Name.
- Choose the operator: Contains, Is, Starts with, or Ends with.
- Type the parameter on which you want to base the rule.
- Select the data label: PCI, PII, PHI. You may add more than one.
- Don't forget to click Save.
For example, to tag employee data as Personally Identifiable Information (PII), you might create the following rule:
If Asset Name start with Employ then add PII
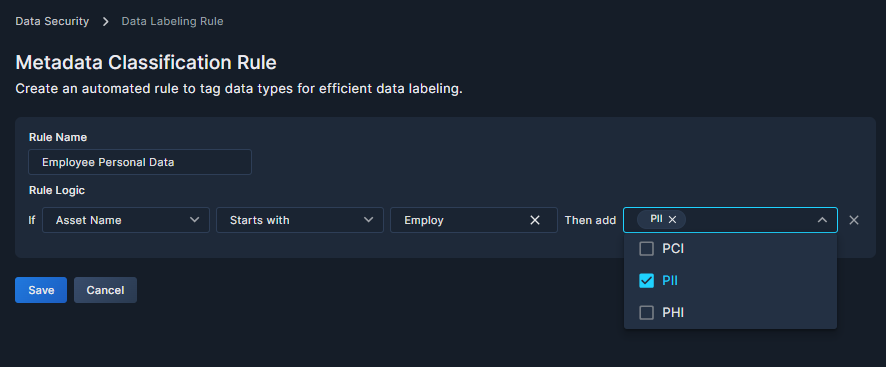
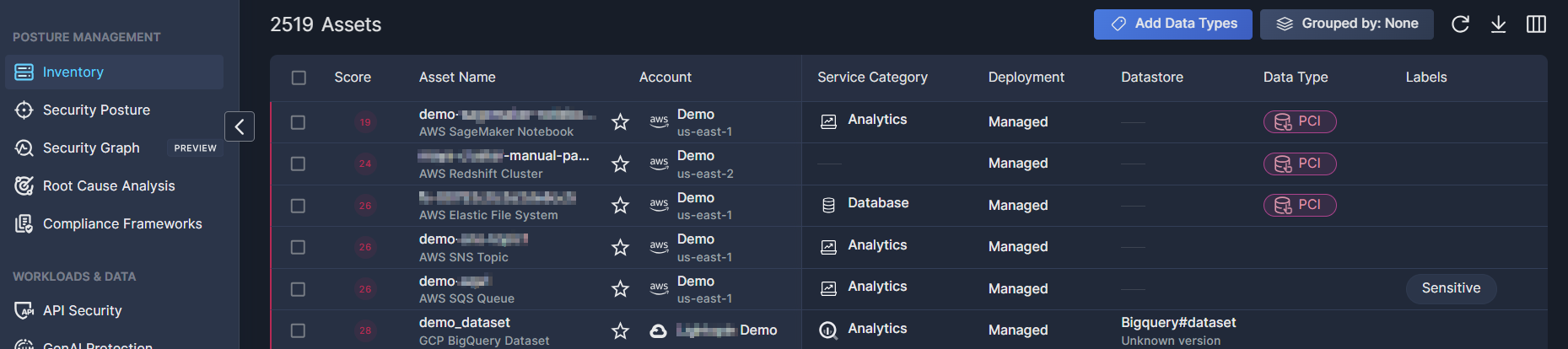
The metadata classification rules you create are applied during the daily scan, assigning the selected data types according to the logic you’ve defined in the rule. You can view the results in the Data Inventory subtab of the Asset Inventory tab of Panoptica's console UI. See Data Inventory for details.
Manual Data Classification
You also have the option of adding or removing Data Type and Sensitivity tags on the Data Inventory subtab of the Asset Inventory tab in Panoptica's console UI. See Data Inventory for details.
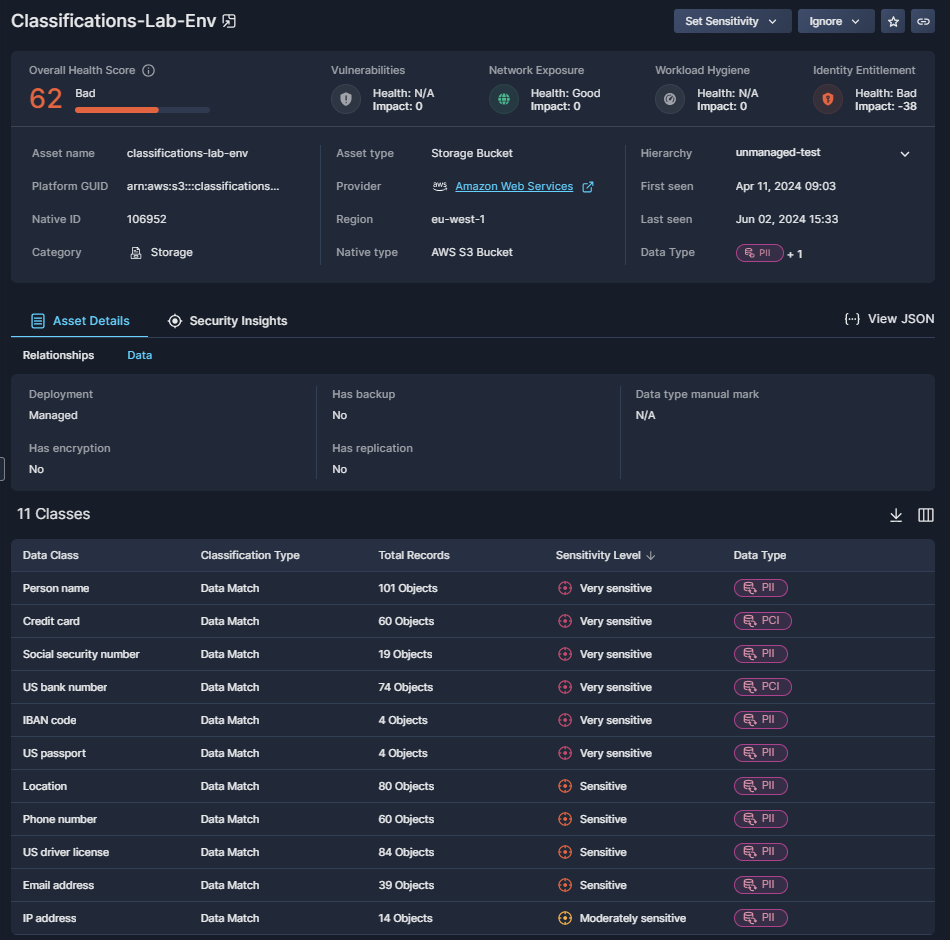
Classification Results
Beyond the summary results that appear in the Data Inventory table, click on a relevant asset to view more Asset Details in the side window. On the Data subtab, you'll be able to view the data classes Panoptica discovered in your environment, with sensitivity levels and data types assigned either automatically or via the classification rules you defined.
Updated 7 months ago